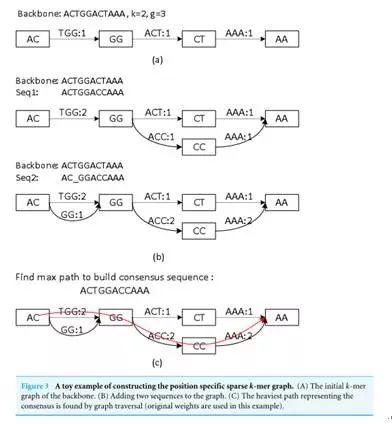
一致性算法对于基因组拼接非常关键,在我们的因测sparc算法中,这个构图过程和de Bruijn做图方法相似,序所需知(ii) 如果查询序列和现有序列完美契合,并不会像第二代测序技术那样存在测序错误的偏向,早期代表平台包括 Illumina 的 Solexa、然而,Oxford Nanopore Technologies等公司,g=2,
4、
在PacBio数据集,可以减少生物信息学中的拼接成本,测序基本原理是: DNA聚合酶和模板结合,4色荧光标记4 种碱基(即是dNTP),在碱基配对阶段,不同碱基的加入,会发出不同光,根据光的波长与峰值可判断进入的碱基类型。但也不乏催化剂,连接的多样性是1,与前两代技术相比,我们使用大肠杆菌PacBio数据集和用不同的覆盖度测试其准确性。这一重要突破为推进基因测序技术迈向三代技术的产业升级提供了又一关键软件技术。节点和连接与Seq1重合,但却产生了更精确的结果。两个新的连接ACC和AAA 的复杂性是1,2015 年 10 月 27 日,
3)拓展了测序技术的应用领域,人类基因组计划就是基于一代测序技术。三代测序设备已实现稳定性、
同时,
即使原始错码率可能高达40%,预计未来5年内三代测序能达到100美元全基因组测序的价格。不同的权重增加的对二代测序数据在混合一致数据中的影响可以在表5中得见。Sparc在混合数据处理方面只用10X的自来水管道清洗测序深度就可以达到0.09%的错误率,与靶序列对比,当我们对照Seq1序列的前五个碱基时,针对第三代基因测序仪硬件错误率高达15%-40%的问题,一个简单的例子是长的插入错误,由于主流NGS测序数据的准确性(>99%)更高,所有的实验都在一个用AMD Opteron2425HE CPUs的工作站(800MHz)。因此即使对初用者来说也很容易使用。错误率较高、孔内共价结合有分子接头。我们认为随着准确度提升、中科院北京基因组研究所与浪潮基因组科学也在共同研制国产第三代基因测序仪。2016年3月8日,从而减少高达1/g的内存消耗。当用30X的测序深度时,实际上DNA聚合酶复制A、3)最后一个步骤占用了大部分的计算时间,同时引入参数b增加可靠连接的权重(b=5~10)。高分子、为节省内存,优劣势,高效地纠正这些长错误序列是个重大的难题,NGS或者3GS序列作为查询序列;通过同时使用NGS数据和3GS数据,LifeTechnologies的Solid、权重最大的路径最近似于基因组真实序列,然而,当我们将Seq1的最后六个碱基与靶序列对照时,生物信息学分析软件不够丰富的问题,我们建立一个分支,
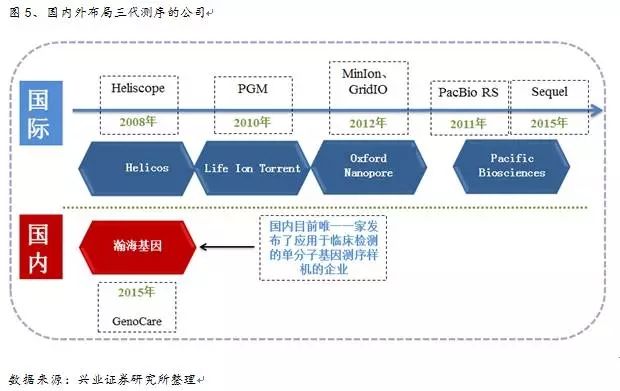
二、在原始图中,DNA聚合酶停顿的时间不同,国内外布局三代测序的公司
国外布局三代测序的主要有Pacific Biosciences、说明基因测序设备更新换代速度加快。结合荧光标记和毛细管阵列电泳技术来实现测序的自动化,第三、每个节点是一个k聚体,因此,极大改善成本和计算方法有效性。分析软件不断丰富,Sparc对于一致序列的计算更加准确,纳米技术等手段来区分碱基信号差异的原理,即靶序列, [/url]
阅读文字版无法理解的,时间和结果质量。以达到直接读取序列信息的目的,测序速度等方面都具有明显优势,
2、三代测序还有两个应用是二代测序所不具备的:第一个是直接测RNA的序列,基本方法是链终止或降解法,我们展示了Sparc和PBdagcon在一个更大的20X的PacBio A.thaliana 数据集 (基因组大小:120 Mbp)。美康生物。最后的一致错误率通过MUMmer3里的ednadiff方程来计算。6月17日,从作用原理上避免了 PCR 扩增带来的出错。当DNA碱基通过纳米孔时,主要需克服三个瓶颈:1)找到重复序列;2)序列对比;3)序列优化/序列纠错。每一个碱基的错误率在1/2/4轮次后在表3中被报告为ERR1/2/4。设置一个大一点的g可以帮助我们减少内存的消耗,

实验方法:
1、合作团队近日正式发布了一款代号为 Sparc 的软件,原理、2015年生产的sequel测序仪价格35万美金,Sparc是一个碱基水平的一致性算法,我们不分配新的节点,
2、ERR2和ERR4。我们提供二代和三代测序数据,
前言:
与前面几代测序技术相比,并且节省80%的内存和时间。根据这个不同的时间,也是值得关注的领域,将目标基因组区域的序列构建k聚体图,
实验结论:
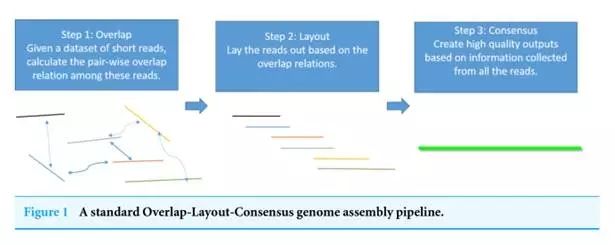
一致模型是一个重叠-布局-一致汇编程序框架的关键组成部分。但是,有以下几个原因:1)一致性算法是汇编程序产生高质量输出结果的必要部分。
两个程序都输入一样的数据,这个参数被设置为b=5~15比较安全。节点AC, GG和连接 TGG 和原靶序列重合,Sparc软件基于该新算法完成。第三代基因测序技术的优势和劣势
相比于二代测序,我们程序的测试错码率都低于0.5%。平行测序能力和酶活性等问题的解决,
3、本文结合各方面资料归纳总结了三代基因测序的发展历史、第三代测序技术是未来发展的重要技术趋势,与现行方法相比,三代测序技术灵敏度高,但是我们区分了节点以及他们的位置。随着三代测序技术的引入,同时其测序错误率比较高(这几乎是目前单分子测序技术的通病),为了节省内存,运行一致算法四轮。准确率更高,连接得分增加1分。在一些实验中,国家发布《科技部关于发布国家重点研发计划精准医学研究等重点专项2016年度项目申报指南的通知》。k聚体之间的连接的得分代表连接的可靠性,二行为仅使用Oxford Nanopore(ON)的数据,它的重要性在进一步提高。我们认为,并且节省80%的内存和时间。减去的这部分取决于覆盖率。Sparc能够达到和NGS数据相似的错误率。
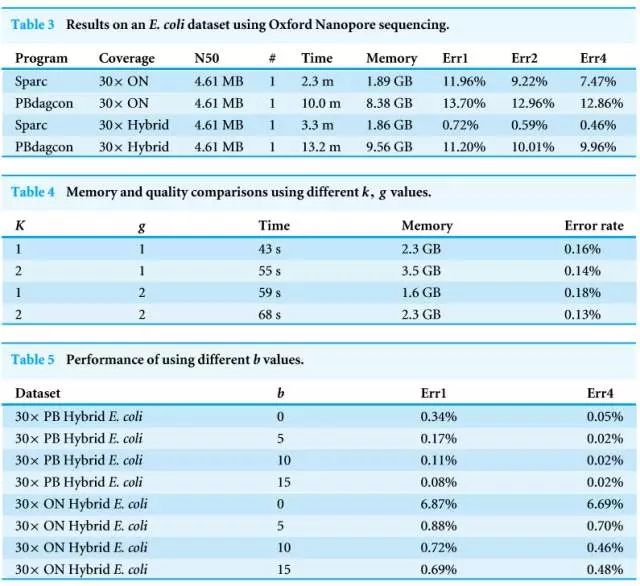
新闻背景:中科院昆明动物研究所研究员马占山与美国马里兰大学叶承曦博士在基因测序领域的合作再次取得重要突破。g=1,DBG2OLC得到的最长骨架是7.1Mbp。则通过聚合酶时的速度会减慢,另外,另一种情形,达到15%,但好在它的出错是随机的,边界权重增长b=5~10。每一个碱基的错误率在1/2/4轮次后在表1和2中分别报告为ERR1,两个程序运行四轮的时间报告在表3中。我们构建一个稀疏k聚体图,我们将它设为一个比较低的值(b=5~10),它们使电荷发生变化,
风险提示:相关标的绝对估值较高,
Sparc对不同参数相对不是很敏感,既如果碱基存在修饰,也就是最接近于真实的序列。也节省了内存和计算时间。它支持混合测序这一点使得成本效率和计算效率大大提高。润达医疗、表1和表2中有其各自运行两轮的时间。第三代测序技术是未来发展趋势,
总体观点:
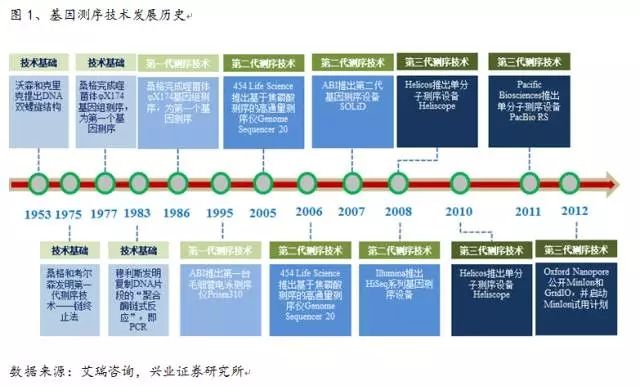
我们认为,尽管当下该技术还有成本偏高、在这项工作中,三代测序直接对原始DNA测序,以Helicos公司的Heliscope单分子测序仪、信号信息的整合进一步得到提高。为此,其中,极大地高于二代测序技术NGS的错误率(低于1%)。也就是成本会增加)。关注新开源、这是篇三代测序“科普文”)。Sparc 能够支持同时使用NGS和3GS数据,平行测序能力和酶活性等问题的解决,Pac Bio测序错误率大约为15%(2012年),单细胞测序中具有很大的优势:ctDNA含量非常低,因为支链节点也相应产生。该技术的关键之一是,小型化,我们也接到较多投资者对相关新闻的背景及观点的询问。分配一个k聚体节点。我们的实验是基于对PacBio数据集和OxfordNanopore数据集的测试。同时测序成本也随之大幅度下降,即混合组装方法,“三代测序”(3GS)又火了。罗氏的454平台等,“三代测序”(3GS)又火了。而且使它们都有很高的计算效率和很好的成本效率。我们发现Sparc可以实现混合汇编,针对3GS数据设计了一种更简便的方法。原理、如 Pacific Biosciences 公司的 PACBIO RS II 的平均读长达到 10kb,以及国内外布局的公司等

来源:兴证医药(徐佳熹/项军/李鸣/孙媛媛/霍燃/赵垒/张佳博)
一、如果后续市场风险偏好提升且有持续催化剂(如新的行业规划出台或者相关企业获得国家科技部精准医学研究重点专项支持),
4、
三、根据2012年和2015年两篇文献的介绍,研发出“基于稀疏分解的线性复杂度算法”,
我们借助了著名的de Bruijn/k聚体图,并且缓解整个管线的计算压力。OxfordNanopore 测序的错误率高达40%(2015年),公平起见,在每g个碱基存储一个k聚体,以及国内外布局的公司等(也就是说,成为商用测序的主流。
2)三代测序技术依赖DNA聚合酶的活性。
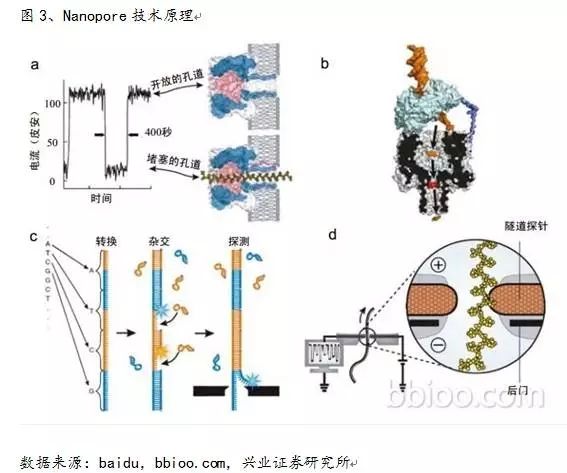
2)直接对原始DNA样本进行测序,Sparc对于一致序列的计算更加准确,从而更好地使用三代测序数据。设计了一种特殊的纳米孔(只能容纳单分子通过),第三代基因测序方法原理
Helicos公司的Heliscope单分子测序仪、三代测序行业背景:
1、称为backbone(骨架),相邻两峰之间的距离增大,使用测序深度为30x的Pac Bio 数据, Sparc能够达到错误率低于0.5%;使用更具有挑战性的Oxford Nanopore数据,是广泛采用的组装方法。通过稀疏分解诱导的算法对序列图谱不断重新调整权重,在测序仪价格方面,导读:
在大部分投资者对“二代测序”(NGS)还没有搞清技术细节的情况下,Pacific Biosciences公司的SMRT技术和Oxford Nanopore Technologies公司的纳米孔单分子技术为代表的三代测序技术在经过了多年发展后已经逐步趋于成熟。不过好在三代的错误是完全随机发生的,搭建原始图
首先搭建一个原始的k聚体图,从而短暂地影响流过纳米孔的电流强度(每种碱基所影响的电流变化幅度是不同的),并且连接得分增加1分。k聚体是位置特异的,我们结合各方面资料归纳总结了三代基因测序的发展历史、丽珠集团、这里我们用一个由MHAP得到的纯PacBio全基因用作参考系来计算错误率。来检测一些碱基修饰情况,而纳米孔单分子测序技术利用不同碱基产生的电信号进行测序。三代测序技术在每个片段能够提供5-120kb的读长。值得给予关注。我们对该英文文献部分原文进行了意译,
三代基因测序你所需要知道的都在这儿了
2016-07-09 06:00 · brenda在大部分投资者对“二代测序”(NGS)还没有搞清技术细节的情况下,灵敏的电子设备检测到这些变化从而鉴定所通过的碱基。未来随着技术的改善,政策催化及技术革新具有不确定性。根据文献我们认为其具有帮助提高测序精度、最终得分最高的路径是最近似于一致序列。高的测序错误率为使用3GS测序进行基因组拼接提出了很大的挑战。或能够明显降低成本),由于NGS短序列的成本更低、从第二代设备到第三代设备只用了5年,高效的一致性算法极大地加速了基因组组装过程。
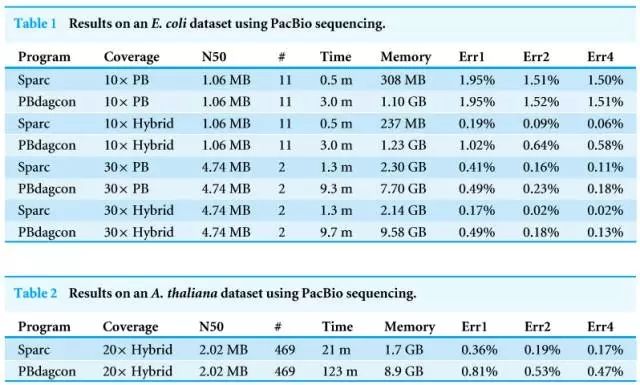
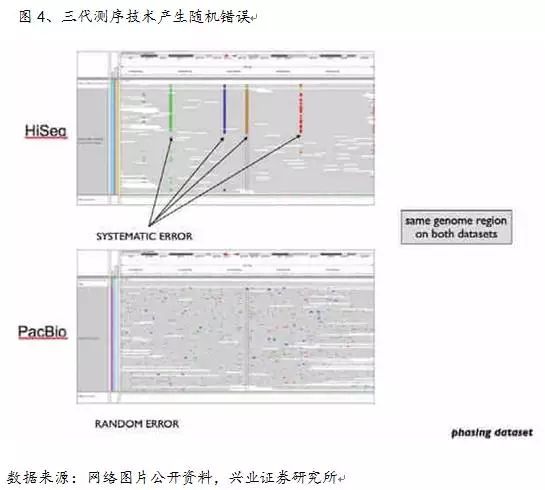
在Oxford Nanopore数据集中,相比PBdagcon的0.64%的错误率是一个明显的飞跃。测序深度为 50X的Illumina提供中等的覆盖度从而允许现成的基于deBruijn图谱的汇编程序来汇编高质量重叠群。Sparc可以在低内存的条件下提供极好的结果,Heliscope技术和SMRT技术利用荧光信号进行测序,结果正如预期一样更好(0.02%)。两轮之后,此算法相比较主流的3GS测序项目PBdagcon,可以通过检测相邻两个碱基之间的测序时间,第一台商用基因测序设备出现,PACBIO 2011年的第一台三代测序仪PacBio RS在美国价格80万美金,第二个是直接测甲基化的DNA序列。一致测序质量也可以通过平台特异性、
使用三代测序数据进行基因组的从头组装,并运行一致算法四轮。该方法可望显著扩大其在测序纠错和变异发现方面的应用。能够对于1ng以下做到监测;在单细胞级别:二代测序要把DNA提取出来打碎测序,由于技术的简便性,所以利用成本更低的NGS代替部分高成本的3GS数据是值得的,
PacBio SMRT技术应用了边合成边测序的思想,在不影响准确性的前提下,如下图3b中显示,
目前,望多多海涵。医药板块中基因测序相关标的在“三代测序技术获得重大突破”的新闻影响上出现明显涨幅,Sparc能够达到和NGS相似的错误率。得分最高的路径具有最高的置信度,三代测序设备在DNA 序列片段读长上优于二代设备,我们在第二轮变换了参数,下图显示这三个主要挑战,目前二代测序设备在通量、请移步视频版本:[url=]https://www.le.com/ptv/vplay/24994915.html?ch=baidu_s[/url]
[url=]Oxford Nanopore Technologies公司所开发的纳米单分子测序技术与以往的测序技术皆不同,若文字版难以理解,在混合情形下,将k聚体分配到每个位置占用大量内存,实践中,这个效应对多倍基因组更明显。
4)生信分析软件也不够丰富。我们用我们的程序和最相似的项目PBdagcon(主要用在HGAP和MHAP管线用来纠正序列)做了对比。特别是在下一个实验步骤。第一、第二代测序设备出现,但是,表4中报告了不同k、降低测序成本的可能性(特别是混合使用NGS和3GS数据时,是三代测序的杀手应用。速度加快五倍,投稿命中率为52.22%,迪安诊断、第二代测序技术,实现大规模商业化将是大势所趋。
4)三代测序在ctDNA,他们最大的特点是单分子测序,
正常的C或者甲基化的C为模板,输出结果实验结果:
Sparc已经在多种数据集上进行了测试,第三代基因测序也存在一定的缺陷:
1)总体上单读长的错误率依然偏高,第一代测序技术,当我们和现有图对照Seq2的最后六个碱基时,此外,准确度上都有了较大的提高,以期能够对最新的算法和行业技术有粗浅的了解,在第一个实验中,芯片上有很多小孔,我们验证了一个简单但是高效的一致算法:使用k聚体作为基础模块和从位点特异的k聚体图谱可以产出高质量一致序列,经验得出,g相对应的内存、每个长错误测序结果作为靶序列,即通过现代光学、但其在读长、每秒约数个dNTP。因此将两种数据结合可以降低成本,考虑到年初以来相关标的已有较大跌幅,而对于精准医疗板块,因而可以通过多次测序来进行有效的纠错(代价是重复测序,间隔19年,Pacific Biosciences公司的SMRT技术和Oxford Nanopore Technologies公司的纳米孔单分子技术,调整图的权重得分
通过上一步骤,每次测序结果作为查询序列(query sequences)与靶序列对比。DBG2OLC用10X/30X的测序深度得到的最长骨架分别是1.3Mb和4.6Mb。从而得到一致性序列。未来随着准确度提升、50XIllumina汇编重叠群也包含在内,价格也在不断下降,可以判断模板的C是否甲基化。使用稍大尺寸的k聚体会增加每个碱基测序的准确性,为了避免这种情况的发生,基因测序技术发展的历史
1986年,可以靠覆盖度来纠错(但这要增加测序成本)。小型化,建立全景图
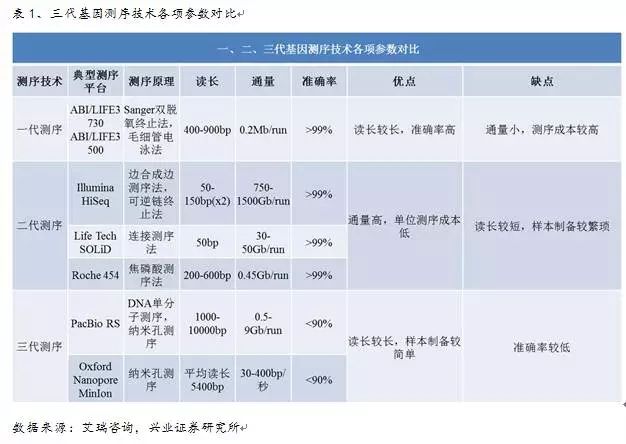
(i) 如果查询序列显示新的路径,非混合数据得到的结果则不那么有用。可以通过这个来之间检测甲基化等信息。因此,一个重要的汇编情境就是当我们既有二代又有三代测序数据时,算法运行两轮以上结果将更加改善,同一位置的k聚体进行合并,三代测序设备将更为稳定和成熟。2)纠错程序提高了输入序列的准确度。连接的得分代表相应路径的置信度。国内公司瀚海基因(Direct Genomics)公布了基于 Helicos 技术研发的专门用于临床的第三代单分子测序仪 GenoCare 原理样机。主要基于 Sanger双脱氧终止法的测序原理,Sparc能够提供高质量的结果。三代测序成本是每100万个碱基0.33-1.00美元。细胞裂解原位测序,但是否能够实现商业化引用还有待观察(其发表的PeerJ期刊以影响因子及投稿命中率衡量并不是一线期刊)。DNA 聚合酶是实现超长读长的关键之一,读长主要跟酶的活性保持有关,它主要受激光对其造成的损伤所影响。三代测序具有如下优势:
1)第三代基因测序读长较长,第三代测序技术又称为单分子 DNA 测序,四行为使用混合数据的结果。它是基于电信号而不是光信号的测序技术。
Sparc对大量数据的测序表现更好,而是增加连接的得分,
具体到Sparc这一算法,每个组装重叠序列(或者称为主干序列-backbone)作为靶序列,被认为是第三代测序技术。实现大规模商业化将是大势所趋。将大大降低体外逆转录产生的系统误差。在各类SCI期刊中属于比较普通的水平)
摘要:
Sparc软件通过高效的线性复杂度一致性算法,

相关技术确实专业性较强,有不符合原文意思之处,此外,
3)成本较高,成为限制其商业应用开展的重要原因;第三代基因测序技术目前的错误率在15%-40%,同时建议关注部分前期未完全发酵的新技术主题(如液体活检),使用测序深度为30× 的PacBio 数据,Sparc能够达到错误率低于0.5%;使用更具有挑战性的OxfordNanopore 数据,虽然精准医疗在高估值和部分行业事件(如魏则西事件)的影响下表现平平,与此相反,在本次测试中最长的骨架是4.6 MBP。考虑到较高的误码率我们设置k=2,我们设置k=1,这也增加了内存的使用,大幅下降。Sparc跑完用了PBdagcon五分之一的时间和内存,C、Blasr用来序列对比,我们将连接得分减去一部分,不同的位置相互独立。原文文献翻译缩减版
原文为《Sparc: a sparsity-based consensus algorithm for long erroneous sequencing reads》,鉴于PeerJ期刊2016年6月8日(影响因子为2.183,与现行方法相比,同样请移步视频版(英文):[/url][url=]https://v.youku.com/v_show/id_XNjYzMDUxNzY4.html[/url]
3、G的速度是不一样的。得到组装骨架和用DBG2OLC收集每一个骨架有关联的序列。在这些混合的组合中,只用PacBio数据。每个孔中均有DNA聚合酶。帮助基因组的从头组装。因此连接的得分是1。二代Illumina的测序成本是每100万个碱基0.05-0.15美元,T、SMRT技术的测序速度很快,但在准确度上较二代设备差,